Now is the time for indexing
Written by hand, inspired by Jack and Roelof’s article From Hierarchy to Intelligence
Software is thinning in particularity, while orchestration is taking over. The value is more and more becoming how software can be organised and the moat is shifting towards orchestration, and then finally to the data alone. Salesforce sees this. With slack requiring not only a paid subscription, but a higher rate subscription to export all of the content an organisation has shared with them (including private channels), my gut feel is that they are hoping fewer and fewer orgs will use this feature, and instead opt in for Salesforce to do analytics on their internal data on their behalf. Granted, you have already decided to share your internal data with an external organisation, so employees in that organisation could find your discussions in their logs, but soon, if you decide to opt in to Slack’s own advanced features, you’ll likely expose higher level extracts of your data with another company too. A bad actor or insider no longer needs to sift through gigabytes of logs, they can simply read the “key takeaway” logs and get what they need quickly.
I propose now is the time for every small org to utilise data extraction features from their main stores of intelligence, be it Slack, Teams, Discord or others and start to understand how you can build your own AI features around them. You’ll be in control of the logs for higher level abstractions, key decisions, main takeaways, and can tweak the “Clippy” to do what your organisation needs, and not let it become a generalised intelligence harvesting feature for content providers.
A great first setup, in my opinion looks like the following:
Extracts of your main data sources that impact eachother and can have cross references - let’s say a support platform like Zendesk, a chat platform like Slack and a ticket tracking platform like Atlassian’s Jira. These need to be full extracts - either get them via API or get full downloads on rotation.
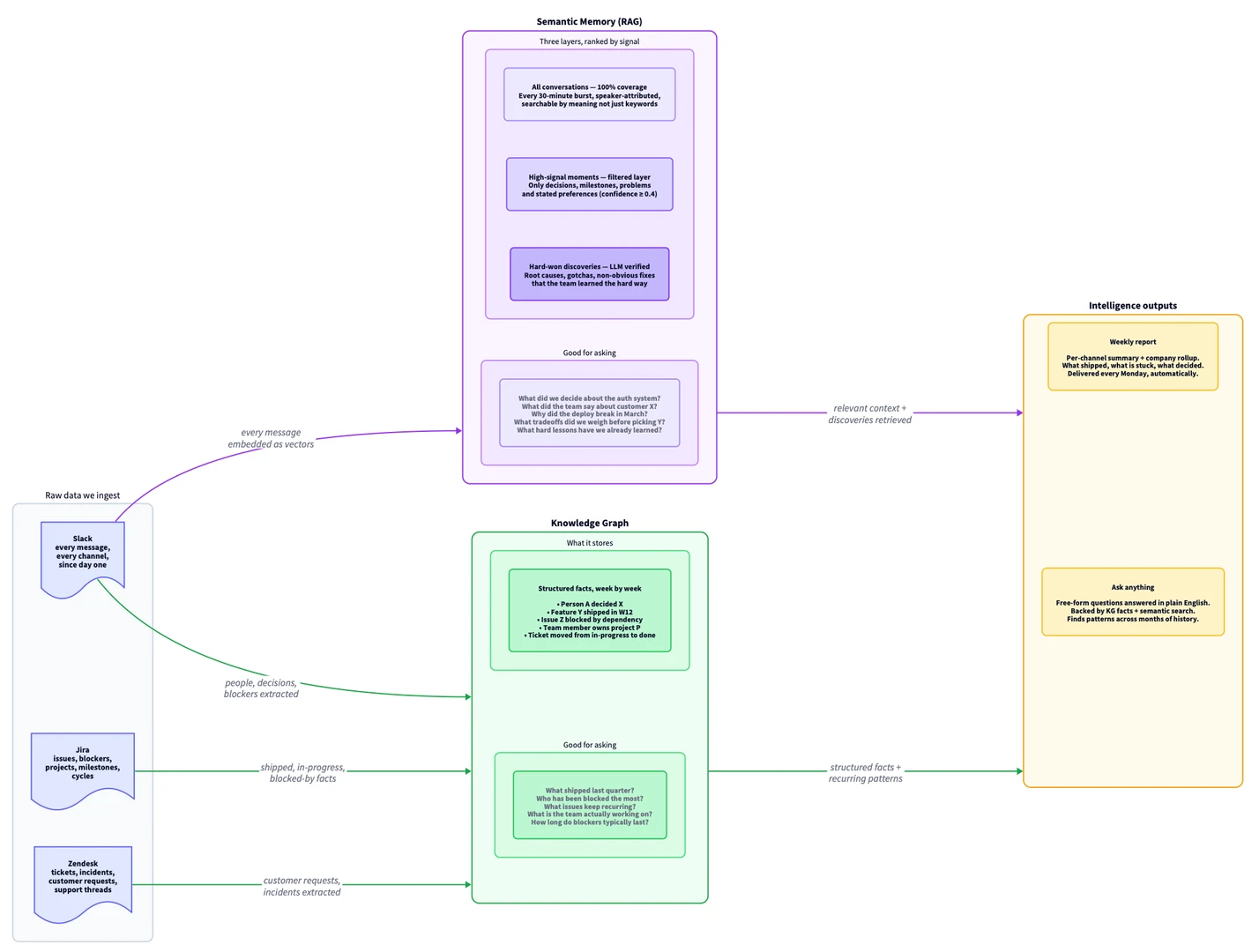
Map these into to separate stores:
A Semantic Memory - turning messages into vectors so it can be searched through by meaning, rather than keyword match (look for “website broken” and find all instances of anything on the website broken too even if the word website wasn’t mentioned.). We convert the input text and store “112394738….” (it’s just a number), and convert the search text and look for (“112395738…”) and find the match between those meanings.
A Knowledge Graph - a much more structured store where very precise “triples” are stored. Meaning here is distilled in the opposite way, we clearly restrict the content and make it easily understandable with very basic searches. We store: website - blocked_by - broken_payment_button
These two together become a powerhouse to build future solutions on top of and help navigate internal company data. By doing this ourselves we decide what AI model to use on them, and where it is hosted (maybe you host it yourself?), and when many enough do this it will be much harder for data processing companies to slowly shut the gates as they realise the main moat they have is your data.
Looking for comments…
Searching Nostr relays. This may take a moment the first time this article is opened.
Looking for comments…
Searching Nostr relays. This may take a moment the first time this article is opened.